🥕 측정 환경
AWS 원격 서버 인스턴스 종류
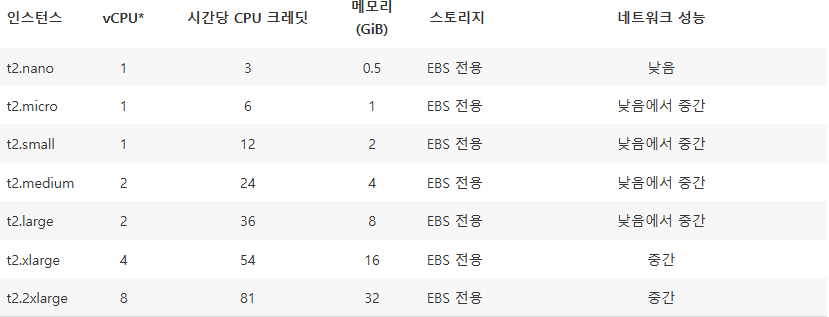
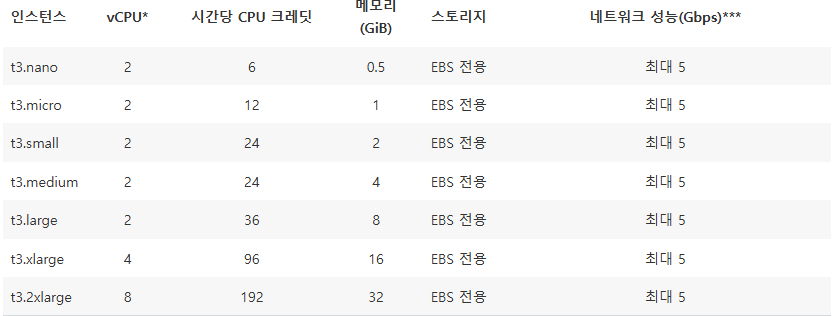
⇒ AWS 홈페이지에 따르면, t3.micro는 2코어 CPU와 1기비 바이트의 메모리를 가지고 있다.
⇒ t2 시리즈의 네트워크 성능은 낮음에서 중간으로 명식적으로 적혀있지 않으나, t3가 더 나은 네트워크 속도를 가지고 있는 게 분명하다 생각하여 t3.micro를 선택하였다.

🥕 스트레스 측정 도구
JMeter

아파치 JMeter 애플리케이션이란, 부하 테스트와 성능 측정을 위한 자바 기반의 소프트웨어이다. 원래는 웹 애플리케이션을 테스트하기 위해 설계되었지만, 이후 다른 프로토콜로도 가능하게끔 기능이 확장되었다고 한다. 스트레스 측정 도구 중 JMeter를 가장 많이 들어보았고, TCP 프로토콜도 지원하기 때문에 선택하게 되었다. 또, 측정 도구가 무엇이냐는 그리 중요하지 않다는 튜터님의 조언도 있었기에 선택을 내리는 데 너무 많은 시간을 할애하진 않았다.
Docker stats

이 프로젝트의 게임 서버는 AWS시작 템플릿을 통해 애플리케이션의 초기 환경을 세팅하게 되어있다. 쉘 스크립트를 user data에 기입하였으며, 도커 허브의 레포지토리에서 게임 서버의 이미지를 불러와 컨테이너로 실행한다.
ubuntu 환경에서 도커를 사용하고 있기 때문에 아래 명령어를 통해 성능을 측정하였다.
sudo docker stats [컨테이너 이름]

각 컬럼의 의미는 다음과 같다.
- CONTAINER ID: 컨테이너의 아이디. 컨테이너가 생성되면 자동으로 부여되는 식별자.
- NAME: 컨테이너의 이름.
- CPU %: 컨테이너가 사용하는 CPU의 비율.(2코어 기준 200%가 MAX)
- MEM USAGE / LIMIT: 컨테이너가 사용하는 메모리 양과 컨테이너에 할당된 메모리 리밋값.
- MEM %: 전체 할당된 메모리 대비 사용 중인 메모리의 비율.
- NET I/O: 네트워크 인터페이스를 통해 전송된 데이터의 양.(NET I/O: <송신한 데이터> / <수신한 데이터>)
- BLOCK I/O: 블록 스토리지 디바이스를 통해 읽고 쓴 데이터의 양.
🥕 JMeter 설정하기
🌕 스레드 그룹 설정

⇒ 100 명의 클라이언트가 3번의 요청을 동시에 수행하도록 설정했다.
🌕 TCP 샘플러 설정

🌕 TCPClient classname

jmeter의 TCP Protocol Support 플러그인에서는 TCP 서버에서의 Load Test를 위한 다양한 기능을 제공한다.


별도로 플러그인을 설치하지 않으면, jmeter에서는 텍스트(string) 형태의 패킷밖에 보낼 수 없다.
그러나 이 프로젝트에서는 패킷의 내용을 구글 프로토콜 버퍼를 통해 바이너리 형태로 직렬화하고 있다. BinaryTCPClientlmpl 이라는 클래스 코드를 선택하여 16진법으로 변환된 패킷을 테스트에 사용할 수 있었다.
🌕 EOL 설정

⇒ jmeter를 한 번 실행했을 때, 서버에 남는 로그를 캡쳐한 사진이다.
⇒ jmeter 샘플러가 C2S_PlayerMove 패킷을 전송하면 서버는 S2C_PlayerMove 패킷으로 응답한다.
⇒ 응답 패킷을 직렬화한 버퍼를 출력해본 결과, 16진법 숫자로 1f(31)로 끝나므로 샘플러 설정에서 End of line을 31로 설정하였다.

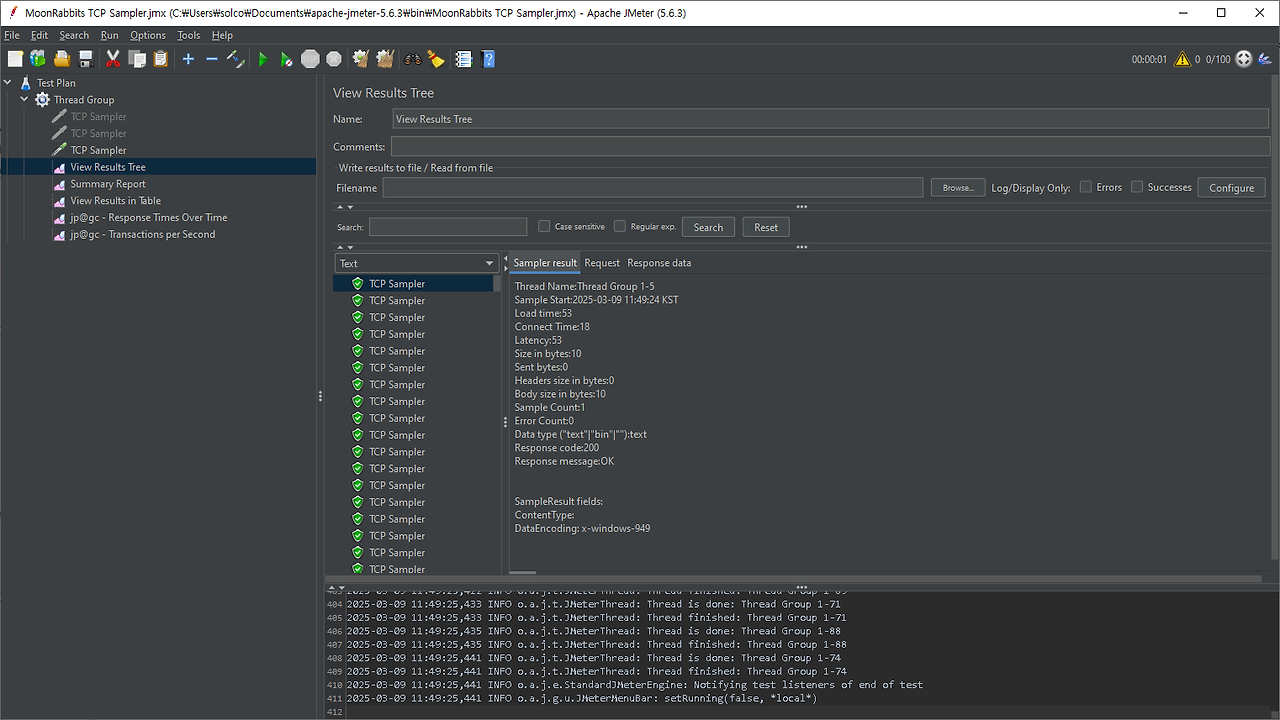
⇒ 100개의 클라이언트가 전송한 패킷이 모두 성공적으로 응답을 받아냈다. 패킷 전송을 총 3번 반복하게 설정했으므로 300개의 샘플이 결과로 도출되었다.

🐰 BEFORE

- CPU %: 0.95
- MEM USAGE / LIMIT(MiB): 116.2
- MEM %: 12.71
- NET I/O(kB): 13.3/8.11(요청/응답)
🐰 AFTER
🥕 CASE1 : 100명의 클라이언트가 3번의 요청을 보낼 때

- CPU %: 37.45
- MEM USAGE / LIMIT(MiB): 121.6
- MEM %: 13.30
- NET I/O(kB)(요청/응답): 269/362
- 평균 레이턴시(ms): 379(1차 테스트 결과), 152.96(2차 테스트 결과)
AWS 모니터링 결과(12:00 ~ 12:15 사이의 그래프)

🥕 CASE2 : 300명의 클라이언트가 3번의 요청을 보낼 때



- CPU %: 92~98
- MEM USAGE / LIMIT(MiB): 146.9~155
- MEM %: 13.30
- NET I/O(kB)(요청/응답): 669/923(1차 테스트 결과), 374/509(2차 테스트 결과)
- 평균 레이턴시(ms): 520(1차 테스트 결과), 488(2차 테스트 결과)
CPU 사용량이 100퍼센트 가까이 도달한 것을 확인했다. t3.micro는 2코어를 사용 중이므로 CPU 가용량 중 50퍼센트 정도를 사용하였다고 볼 수 있다.
AWS 모니터링 결과(12:15 이후의 그래프)

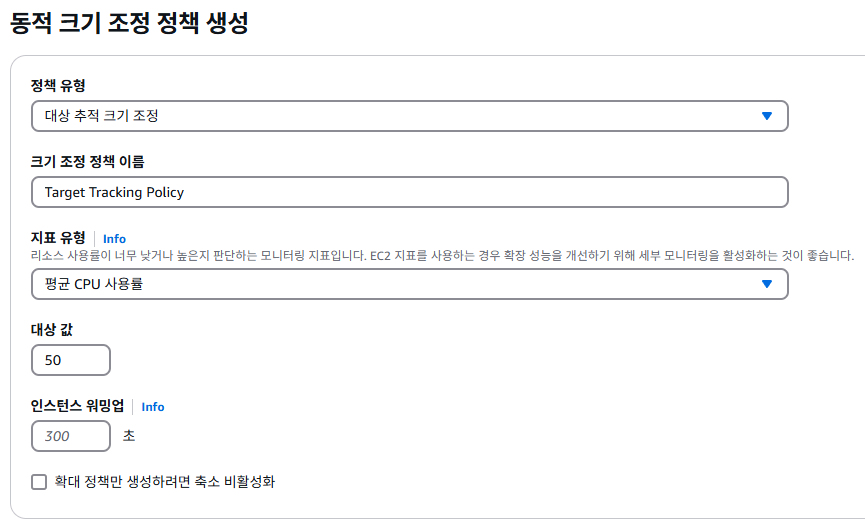
⇒ 부하 테스트 진행 중, 오토 스케일링 서비스로 인해 인스턴스가 늘어난 모습을 확인했다.(CPU 사용률이 50퍼센트 이상일 때 새로운 인스턴스가 생기도록 설정했기 때문이다.)

⇒ 성능 측정 결과로만 보면 큰 이상은 없었지만 2차 테스트 중 응답 패킷 반환에 실패한 케이스가 발견되었다.
⇒ 총 900개의 요청 중 80개가 실패한 것으로 확인됐다.
⇒ 실패한 케이스에서 레이턴시가 0으로 나왔기에 해당 케이스를 제외하여 레이턴시를 새로 구해보면 535.96ms로, 1차 테스트 결과(520ms)와 비슷하게 나온다.
결론
⇒ 부하 테스트 결과 100명 기준 150~370ms의 지연 속도가 발생했으므로, 실시간 멀티 플레이 환경에서 불쾌한 경험을 줄 수 있음을 확인했다.
⇒ 더 빠른 네트워크 속도를 제공하는 t4 시리즈로 인스턴스 타입을 변경할 수 있겠으나, 현실적으로 100명의 플레이어가 게임을 실행할 가능성이 낮다고 생각하여 t3.micro를 그대로 사용하기로 결정했다.
⇒ 왜냐하면 게임 장르의 특성 상 판정의 동시성이 중요하지 않고, 실시간성이 매우 높은 편도 아니며, 이동에 있어서는 추측 항법을 적용했기에 일정 수준 보완이 가능하기 때문이다.
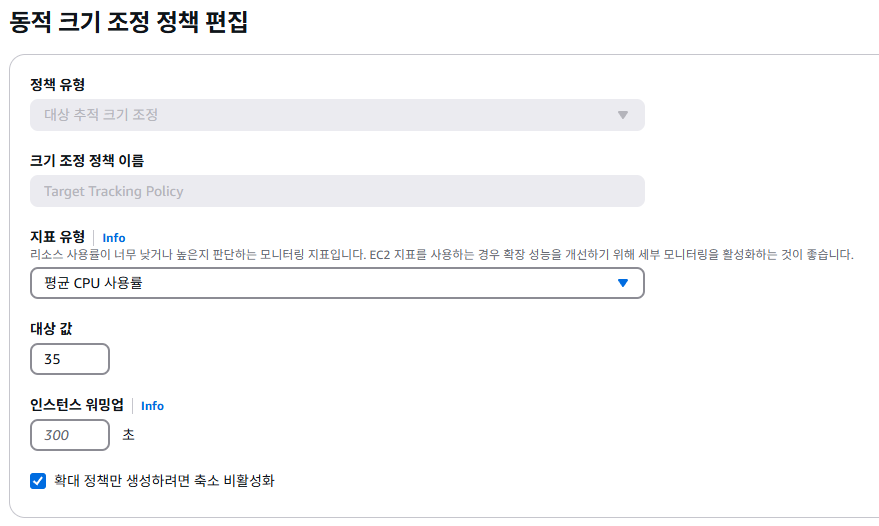
⇒ 따라서 100명 이하, 즉 CPU 사용률 35% 수준에서 오토 스케일링 정책을 실행하는 게 바람직하다고 결론 지었다.
'JS > TIL(Today I Learned)' 카테고리의 다른 글
| 2025-03-12 <최종 프로젝트 D-2> 리드미 작성 (0) | 2025.03.12 |
|---|---|
| 2025-03-11 <최종 프로젝트 D-3> EC2 서버 Brute Force 공격 대응하기 (0) | 2025.03.11 |
| 2025-03-07 <최종 프로젝트 D-7> AWS EIP, NLB, 오토 스케일링을 통해 서버 배포하기 (1) | 2025.03.07 |
| 2025-03-06 <EC2(ubuntu) 도커 초기 환경 설정> (0) | 2025.03.06 |
| 2025-03-05 <최종 프로젝트 D-9> (2) | 2025.03.05 |

댓글